Quark: Real-time, High-resolution, and General Neural View Synthesis
SIGGRAPH Asia 2024
*Denotes Equal Contribution
Overview
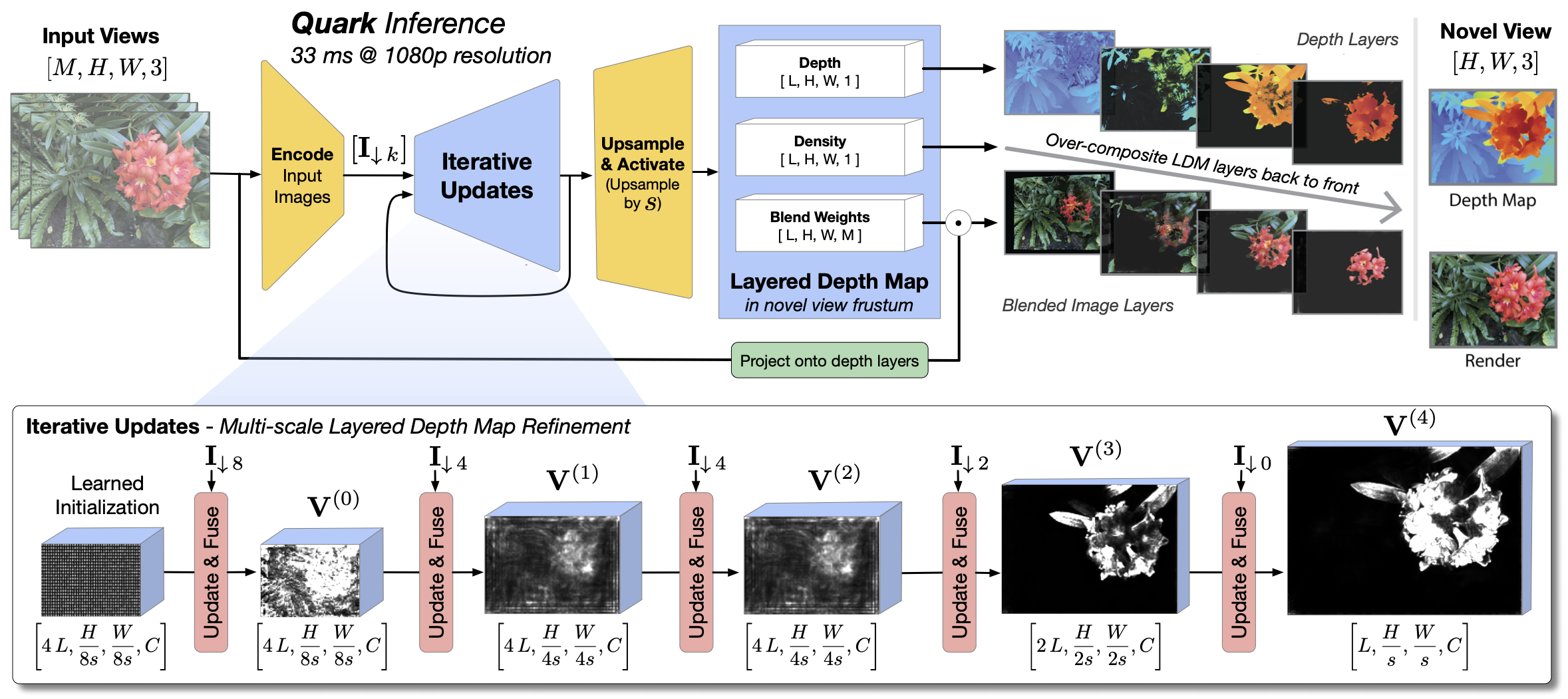
We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous work that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, optimizing the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates.
Video Result Comparisons
Image Result Comparisons
We evaluate our method against various baselines across a diverse set of datasts below. We first compare our method with ENeRF, SIMPLI, and GPNR on Real Forward-facing, Shiny, and Neural 3D Video datasets. We then comapre our method with 3DGS, Instant NGP, MipNeRF-360, Nerfacto, ZipNeRF on the DL3DV dataset. Finally, we show





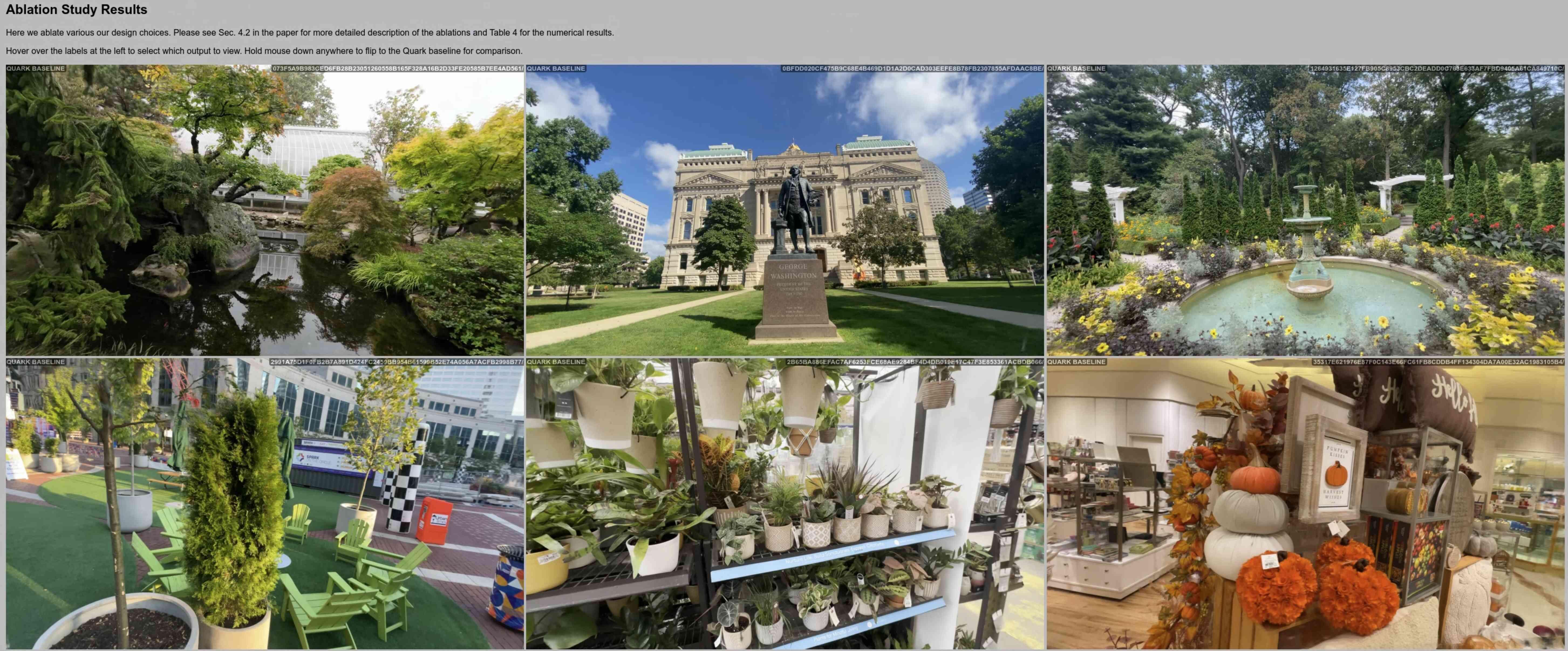
Ablation Study
We first ablate our design choices and show corresponding image comparisons. We then present video result comparsions of two variants of our method, Quark and Quark+.

Acknowledgments
The authors would like to thank Peter Hedman and Ricardo Martin-Brualla for thoughtful discussions and feedback during the course of this research. We are also grateful to the DL3DV authors, especially Lu Ling, for their help in preparing evaluations using their dataset. We thank Alexander Familian for his help editing and doing the voice over for our submission video. And finally we would like to thank Jason Lawrence and Steve Seitz for their unfailing encouragement and support for this work.
BibTeX
@article{10.1145/3687953,
author = {Flynn, John and Broxton, Michael and Murmann, Lukas and Chai, Lucy and DuVall, Matthew and Godard, Cl\'{e}ment and Heal, Kathryn and Kaza, Srinivas and Lombardi, Stephen and Luo, Xuan and Achar, Supreeth and Prabhu, Kira and Sun, Tiancheng and Tsai, Lynn and Overbeck, Ryan},
title = {Quark: Real-time, High-resolution, and General Neural View Synthesis},
year = {2024},
issue_date = {December 2024},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {43},
number = {6},
issn = {0730-0301},
url = {https://doi.org/10.1145/3687953},
doi = {10.1145/3687953},
journal = {ACM Trans. Graph.},
month = nov,
articleno = {194},
numpages = {20},
keywords = {neural rendering, novel view synthesis, layered mesh representation, real-time feed-forward models}
}